Primeros pasos en NLP con spaCy, un vistazo general.

spaCy es una biblioteca para el procesamiento avanzado de lenguaje natural en Python y Cython. Se basa en las últimas investigaciones y se diseñó desde el primer día para ser utilizado en productos reales. spaCy viene con modelos estadísticos pre-entrenados y vectores de palabras, y actualmente admite tokenización para más de 49 idiomas. Cuenta con modelos de redes neuronales convolucionales de alta tecnología para el etiquetado, el análisis y el reconocimiento de entidades nombradas, así como una integración de aprendizaje profundo y fácil. Es un software comercial de código abierto, publicado bajo la licencia MIT.
Muy bien el primer paso es realizar las importaciones.
import spacyPara generar un análisis se tiene que crear un objeto del modelo. Existen varias formas de cargar un modelo, como son: con el enlace de acceso directo del modelo , el nombre del paquete o la ruta al directorio de datos
Se introduce el texto que se va a analizar de la siguiente forma (como un string):
- Analizando el texto con Spacy, la variable doc contiene una versión analizada del texto, aunque aparentemente se mantuvo sin cambios se generaron atributos y propiedades partidas del análisis del texto.
doc=nlp(texto)
print(doc)
Tokenización en oraciones
a continuación se muestran el código para tokenizar oraciones, utilizamos el método “numerate” para enumerar los items obtenidos en este caso los tokens. cuando se tokeniza una oración técnicamente lo que el programa realiza es separar por puntos (bueno en realidad es mucho mas complejo que eso; pero es lo que parece).
#Para tokenizar oracionesfor num,oracion in enumerate(doc.sents):
print(f'{num}: {oracion}')

Comienzan a notarse las deficiencias que existen en modelos en español, puesto que las oraciones no cuentan con dimensiones homogéneas, posteriormente resolveremos este problema mediante entrenamiento, mientras imaginemos que todo va bien.
Tokenización de palabras
Para analizar elemento por elemento lo único que hacemos es leer todo el documento y mandar dato por dato (aquí mando solo 10).
#Para tokenizar palabras
for palabra in doc[:10]:
print(palabra.text)
# Para hacer una lista de tokens
lista_palabras=[palabra.text.replace('\n','') for palabra in doc[:30]]
print(lista_palabras)
Forma de las palabras
La forma de las palabras es algo muy simple, se coloca una X mayúscula cuando esta en mayúscula la letra y en minúscula en el caso contrario, dando estructuras de Xxxxx ademas si se introduce un numero este también tiene su propio valor en cuyo caso es una d, finalmente se muestra si esta palabra contiene caracteres alfanuméricos con un True de lo contrario un false.
#La forma de las palabras y saber si la palabra contiene caracteres #alfanumericos,si si devuelve True.for palabra in doc[:20]:
print(palabra.text,palabra.shape_,palabra.is_alpha)

Etiquetando partes de un discurso
Una vez realizado tu pipeline y procesada la información con los elementos ya tokenizados puedes ver sus atributos, que te ayudaran a definir ciertos parámetros como el tipo de elemento en el lenguaje, la relación con otros tokens entre muchas otras cualidades con las que cuenta el token, a continuación se muestran las mas típicas, para mas información revisar. https://spacy.io/api/token#attributes
pos_ = tipo de palabra por ejemplo sustantivo, verbo, preposición
tag_ = revisión minuciosa de la cualidad anterior especificando parámetros dentro de la categoría
dep_ = relación de dependencia sintáctica
for palabra in doc[:10]:
print((palabra.text,palabra.pos_,palabra.tag_,palabra.dep_))
Con el siguiente método nos devolverá la explicación de un termino para mas elementos y entender mejor revisar.
https://github.com/explosion/spaCy/blob/master/spacy/glossary.py
spacy.explain('amod')'adjectival modifier'
Dependencia Sintáctica
El visualizado de dependencias “dep” muestra etiquetas de parte del discurso y dependencias sintácticas. se coloca el texto a analizar y con el “displacy.render” podemos observar de forma gráfica como se relacionan estos elementos de forma gráfica.
más información en https://spacy.io/api/top-level#displacy_options
from spacy import displacyex=nlp('Miriam ama a Luis')
displacy.render(ex,style='dep',jupyter=True)
Miriam PROPN ama VERB a ADP Luis PROPN nsubj case obj

Realizamos el mismo análisis con un texto mas grande y el resultado fue el siguiente, para mejorar la visualización de los datos usaremos un estilo diferente:
displacy.render(doc,style='ent',jupyter=True)
Lematización
La lematización asigna las formas básicas a las palabras es decir si tenemos las palabras juego, jugaremos, jugaron , jugábamos , la forma base es el verbo Jugar, para mas información https://spacy.io/api/lemmatizer.
docex=nlp('estudiar estudioso estudia estudio estudiando estudiante estudiaba estudió')
for w in docex:
print(w.text,w.lemma_,w.pos_)
Reconocimientos de Entidades
Los modelos de entrenamiento del Corpus de ontoNotes 5 soportan varias entidades como:
PERSON Personas, incluso ficticias. NORP Nacionalidades o grupos religiosos o políticos. FAC Edificios, aeropuertos, carreteras, puentes, etc. ORG Empresas, agencias, instituciones, etc. GPE Países, ciudades, estados. LOC Ubicaciones no GPE, sierras, cuerpos de agua.
para mas información revisar: https://spacy.io/api/annotation buscar “Named Entity Recognition”.
for palabra in doc.ents[:15]:
print(palabra.text,palabra.label_)
Si nos nace la duda con alguna etiqueta podemos hacer lo siguiente: De esta manera nos mostrara cual es el significado de dicha etiqueta.
spacy.explain('MISC')'Miscellaneous entities, e.g. events, nationalities, products or works of art'
Similaridad
spaCy puede comparar dos objetos, y hacer una predicción de cuán similares son . Predecir similitudes es útil para crear sistemas de recomendación o marcar duplicados. Por ejemplo, puede sugerir un contenido de usuario similar a lo que están viendo actualmente, o etiquetar un ticket de soporte como un duplicado si es muy similar a uno ya existente. https://spacy.io/usage/vectors-similarity
ex1=nlp('listo')
ex2=nlp('inteligente')
ex3=nlp('gato')ex1.similarity(ex2)0.24447840411896346
A continuación se realiza una comparación de conceptos de forma anidada.
lista=nlp('gato perro leon pez lobo delfin aguila')
for w1 in lista:
for w2 in lista:
print((w1.text,w2.text),' tienen una similaridad de: ',w1.similarity(w2))
Stopwords
Las stopwords es el nombre que reciben las palabras sin significado como artículos, pronombres, preposiciones, etc. que son filtradas antes o después del procesamiento de datos en lenguaje natural (texto).
from spacy.lang.es.stop_words import STOP_WORDS# para observar las palabras dentro de la lista lo único que se # # tiene que hacer eso imprimirprint(list(STOP_WORDS)[:30])

# aproximadamente Spacy tiene 551 palabras en Stop Words
len(STOP_WORDS)551# Para verificar si una palabra es stopword
nlp.vocab['estados'].is_stopTrue# Para agregar mas stopwords
STOP_WORDS.add("y")
El siguiente código ayuda a filtrar las palabras de un texto y de esta manera determinar las palabras que han pasado dicha regla.
#Para filtrar stopwords
lista=[palabra for palabra in doc if palabra.is_stop==False]print(lista[:100])

Un método para limpiar esos espacios entre elementos es buscar los saltos de linea y remplazarlos y mediante el método join lo que hace es que a la lista de strings anteriormente mostrada la introduce en una lista de un solo string pero sin los espacios.
#De manera similar
' '.join([palabra.text for palabra in doc[:120] if palabra.is_stop==False]).replace('\n','')
Fragmentación
Doc.noun_chunks es una iteración sobre la frase sustantiva básica es decir divide el documento en estas frases, después mediante el for recorremos estos elementos y vamos imprimiendo el elemento raíz seguido de sus conectores.
for palabra in doc.noun_chunks:
print(palabra.root.text,'su conector es: ', palabra.root.head.text)
#si deseas dividir el documento en oraciones solo se tiene que usar #el comando sentsfor oracion in doc.sents:
print(oracion)

Encontrar las palabras mas comunes
para encontrar las palabras mas comunes usaremos.
from collections import Counter#Para nombres mas comunesnombres=[w.text for w in nlp(texto) if w.is_stop!=True and w.is_punct!=True and w.pos_=='NOUN']
print(nombres[:50])

word_freq = Counter(nombres)Colocamos los 5 sustantivos mas comunes y el numero de veces que es repetido.
nombres_comunes=word_freq.most_common(5)
print(nombres_comunes)
#Para verbos
verbos=[w.text for w in nlp(texto) if w.is_punct!=True and w.pos_=='VERB']
print(verbos)
word_freq2 = Counter(verbos)
verbos_comunes=word_freq2.most_common(5)
print(verbos_comunes)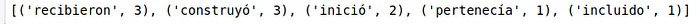
Ahora tienes una visión general de que es lo mas básico que hace spaCy, en las siguientes entradas enfatizaré sobre sus aplicaciones en conjunto con otros software como rasa, NLTK, gensim y otros ademas de aplicaciones dirigidas en entornos de producción, desde la construcción de tu base de datos , hasta como hacer tus propios entrenamientos para mejorar tus identidades.
dejo el enlace de este trabajo para las personas que son mas impacientes:

